Data Foundation
IN THIS SECTION, YOU WILL: Understand how to use diverse data sources to support architecture decision-making processes and get concrete tips on creating architecture-centric data tools.
KEY POINTS:
- The architecture Data Foundation serves as a medium to create a complete, up-to-date picture of critical elements of the technology landscapes of big organizations.
- The Data Foundation provides an architecture-centric view of data about a technology landscape based on source code analyses, public cloud billing reports, vibrancy reports, or incident tickets.
- To facilitate the creation of a Data Foundation, I have been working on creating open-source tools that can help obtain valuable architectural insights from data sources, such as source code repositories. Check out open-source architecture dashboard examples and Sokrates.
“If we have data, let’s look at data. If all we have are opinions, let’s go with mine.” -— Jim Barksdale
Everywhere I worked on creating architectural functions, I strongly (aka obsessively) emphasized data. Consequently, one of the first steps I make in any architecture practice is to create an architecture Data Foundation to get a complete, up-to-date picture of critical elements of an organization’s technology landscapes (Figure 1). Manual documentation does not scale, and relying on data ensures the reliability and scalability of decision-making. In the past several years, I have also been working on creating open-source tools, such as Sokrates, that can help obtain valuable architectural insights from data sources, such as source code repositories or public cloud billing reports.
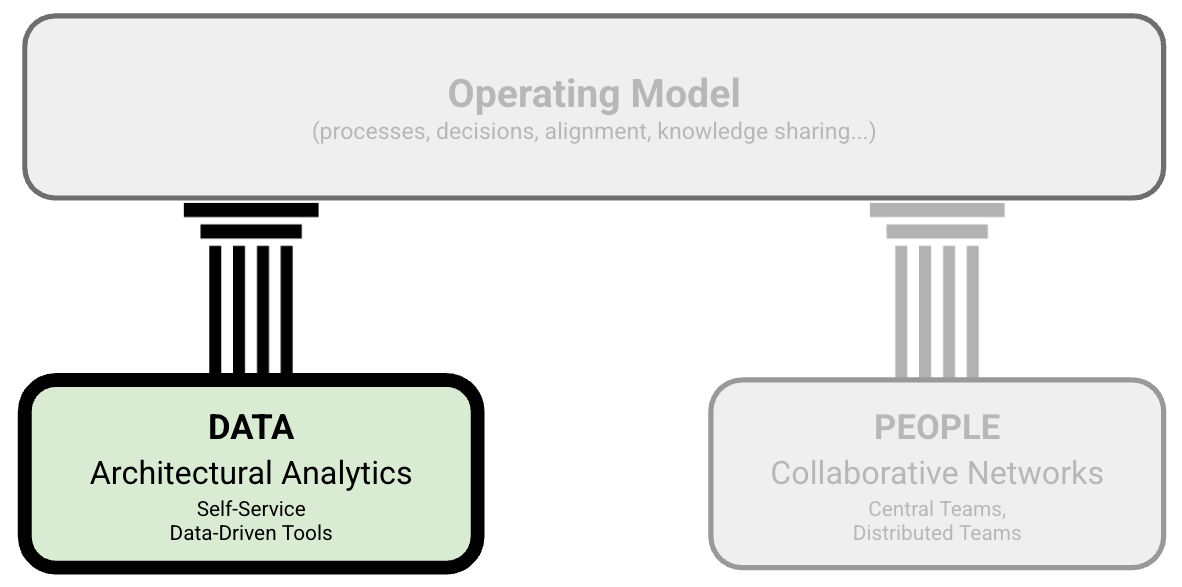 Figure 1: The structure of Grounded Architecture: The Data Foundation.
Figure 1: The structure of Grounded Architecture: The Data Foundation.
The good news is that big organizations have lots of data that, if used wisely, can provide an excellent basis for an architectural Data Foundation. With some automation and curation, getting a crystal clear overview of the technology landscape may be closer than it initially appears.
Examples of Data Foundation Tools
To illustrate what I mean by Data Foundation, I will give a few concrete examples from my recent work. Data I typically used include (Figures 2 and 3):
- Source code contains an incredible amount of information about technology, people’s activity, team dependencies, and the quality of software systems. By analyzing commit histories, code complexity, and contributions, we can identify critical areas of improvement, understand team dynamics, and ensure code quality.
- Public cloud billing reports provide an overview and trends about used cloud services, regions, and budgets. Monitoring billing reports helps manage budgets, identify cost-saving opportunities, and understand usage patterns across different services and regions.
- Incident reports can reveal trends and dependencies among incidents. Analyzing these reports reveals trends, common issues, and dependencies among incidents, helping in proactive problem management and improving system reliability.
- Key business metrics, like vibrancy, which can show user activity on our systems. Tracking these metrics helps in assessing the health of the business, understanding user behavior, and guiding strategic decisions to enhance user experience.
- Messaging and collaboration platforms (such as Slack) activity reports, which can help understand discussion topics and team interactions. Analyzing these reports helps in understanding collaboration patterns, identifying key discussion areas, and improving team communication and productivity.
In the following sections, I detail several of these architectural data-driven tools.

Figure 2: A screenshot of the start page of the architecture data dashboard we’ve built and used at AVIV Group.

Figure 3: A screenshot of the start page of the architecture data dashboard we’ve built and used at eBay Classifieds.
Example 1: Source Code and Commit History
The source code and its commit history are like a treasure chest for creating data-driven architecture documentation—packed with nuggets of wisdom about technology, team activities, dependencies, and software quality. To help dig up this treasure without getting your hands too dirty, I’ve developed and actively maintain a project called Sokrates.
Sokrates is designed with an architect’s x-ray vision, allowing you to zoom in and out of source code landscapes. It provides a high-level overview of the IT landscape, summarizing data from various teams and groups, while also letting you dive deep into the code-level details. This dual functionality makes it the perfect sidekick for both CTO-level strategy powwows and developer-level code critiques.
For a more entertaining look at what Sokrates can do, check out the Sokrates examples. Here are some blockbusters:
- Apache Software Foundation Repositories: An epic saga of over 1,000 repositories with more than 180 million lines of code, 22,000 contributors, and 2.4 million commits.
- Facebook/Meta OSS Repositories: A thriller with 800 repositories, 120 million lines of code, 20,000 contributors, and over 2 million commits.
- Microsoft OSS Repositories: A drama featuring over 2,400 repositories with more than 100 million lines of code, 18,000 contributors, and 1.2 million commits.
- Google OSS Repositories: A blockbuster with over 1,600 repositories, more than 200 million lines of code, 27,000 contributors, and 2.4 million commits.
- Linux Source Code: A classic with 178 repository sub-folders, more than 23 million lines of code, 17,000 contributors, and 1.7 million commits.
- Amazon OSS Repositories: A thriller with over 2,700 repositories, more than 130 million lines of code, 13,000 contributors, and 600,000 commits.
In addition to standard source code and commit history analyses, I also have built several special source code analyses to get further details:
- Travis and Jenkins Analyzers: Perfect for sleuthing how teams build CI/CD pipelines.
- Dockerfile Scan: Creates a tech radar of runtime technologies.
- GitHub API Pull Request Analyses: To identify deployment frequency.
Feel free to use these or similar tools, but I encourage you to experiment with your source-code analyses as well.
Example 2: Public Cloud Usage
Developing in or migrating to the public cloud can dramatically increase transparency thanks to uniform automation and monitoring. The public cloud transparency offers incredibly valuable data out-of-the-box.
Amazon Web Services (AWS), Google Cloud Platform (GCP), Microsoft Azure, and other public cloud providers give detailed data about which platform uses which services, resource family, and budget. You can also understand which people and teams have access to each service. Getting real-time information about cloud usage and automatically understanding the trends is straightforward.
Figure 4 shows the anonymous screenshot of the Cloud usage explorer, a tool I built to visualize automatically-collected data from standard Google Cloud Platform (GCP) usage reports.

Figure 4: An example of a cloud usage explorer.
Example 3: Financial and Vibrancy Data
Finance departments are like Sherlock Holmes in the business world—super data-driven and always on the case with high-quality data that could be a goldmine for architects. Beyond the usual suspects of costs, budgets, and other dry financial stuff, I’ve discovered they also track the fun stuff, like vibrancy and usage levels.
These finance sleuths need this juicy data to, for instance, link the performance of their financial systems with how much they’re being used. This kind of usage data is a secret weapon for architecture discussions. By linking systems’ usage levels and vibrancy with their public cloud costs, we can uncover hidden areas of improvement and inefficiencies (Figure 5).
So, next time you’re knee-deep in architectural plans, don’t forget to call the finance for top-notch data insights!
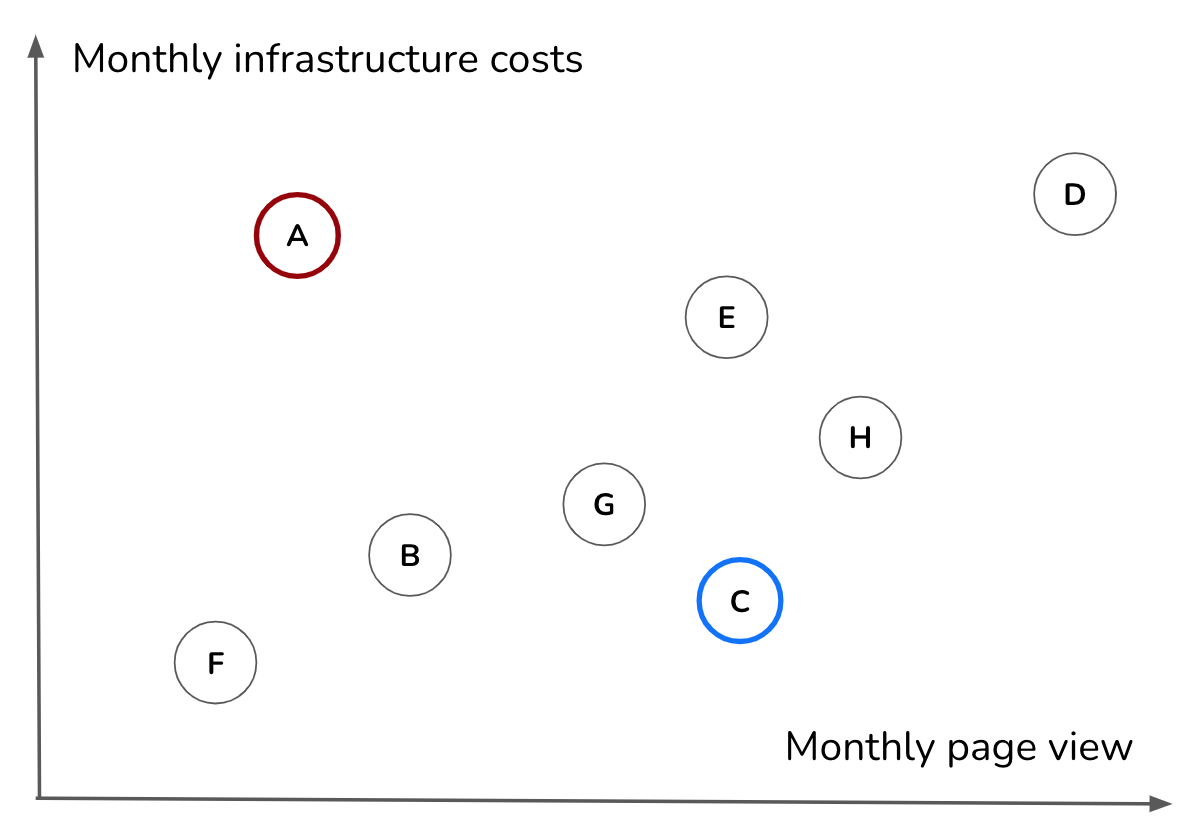
Figure 5: Combining data from a different source (e.g., cloud billing reports and vibrancy or revenue can lead to new insights (e.g., identifying inefficiencies in the application portfolio).
Example 4: Data-Driven Capability Map
Capability models are frequently associated with Enterprise Architecture, providing a structured approach to organizing and managing an organization’s capabilities. Traditionally, these capability maps are maintained manually, which can be time-consuming and prone to inaccuracies. A data-driven version of the capability map enhances this approach by integrating real-time data sources, offering a more dynamic and accurate representation of capabilities. A data-driven version of the capability map enhances this approach by integrating real-time data sources, making the capability map dynamic, alive, and significantly more useful.
I have created several versions of data-driven capability maps, where a capability map includes capability data cards that consolidate various data types relevant to each capability. We then automatically generated sites and visuals from these data for self-service use within the organization. These cards provide a comprehensive view of the current state and performance of each capability, integrating multiple data sources:
- Documentation Data:
- Links to Key Documents: Direct access to important documents related to the capability.
- Automated Summaries: Using generative AI to automatically summarize key documents, making it easier to quickly understand the essential points and status.
- Technical Implementation Evidence:
Source Code Repositories:** These repositories link to and analyze all source code related to the capability, providing insight into the technical implementation.
- Cloud Accounts and Billing Reports: Detailed analyses of cloud accounts, including costs, services used, and geographical distribution (regions).
- Infrastructure Costs and Analyses: Detailed breakdown of the capability’s associated infrastructure costs.
- Legacy Assets List: This is an Inventory of legacy systems and components that are part of or impact the capability.
- Technical Debt Inventory: Identification and assessment of technical debt associated with the capability.
- Planning Evidence:
- Detailed Planning Data: Information from planning systems like Jira, including detailed task breakdowns and timelines.
- Effort Estimates: Projections of the efforts required to develop or maintain the capability.
- Execution Data:
- Product and Business Evidence:
- Documentation of Demos: Links to slides, videos, and other demo materials.
- Product Analytics Data: Metrics such as user engagement (vibrancy), conversion rates, and other relevant analytics.
- HR Evidence:
- People and Teams: Information about the personnel and teams working on the capability.
- Time Tracking Data: Detailed reports on the time spent on the capability by different team members.
- Product and Business Evidence:
Real-time data integration allows for creating dynamic and aggregated views across capabilities. These views can be grouped by criteria, such as domain programs or themes, providing a broader perspective on how capabilities interrelate and contribute to strategic objectives. Examples include:
- Domain Programs: Grouping capabilities by specific business domains (e.g., finance, marketing, operations) to understand domain-specific strengths and weaknesses.
- Themes: Aggregating capabilities around strategic themes or initiatives (e.g., digital transformation, customer experience improvement) to track progress and resource allocation.
Key benefits of a data-driven capability map include:
- Enhanced Decision-Making: Real-time data provides a current and accurate picture of capabilities, enabling better-informed strategic decisions.
- Increased Transparency: Detailed evidence and summaries help us understand the status and needs of each capability.
- Improved Efficiency: Automated data aggregation and reporting reduce manual effort and speed up the analysis process.
- Strategic Alignment: Aggregated views help ensure that capabilities are aligned with broader organizational goals and initiatives.
- Resource Optimization: Detailed cost and effort data help optimize resource allocation and manage budgets effectively.
By leveraging a data-driven capability map, organizations can achieve a more dynamic, transparent, and efficient approach to managing their capabilities, leading to improved strategic outcomes and operational performance.
Requirements For A Data Foundation
A Data Foundation should be a central place with authoritative, relevant, and curated data about the organizational technology landscape. Technically, you can implement Data Foundation tools like those discussed in the previous section, using simple tools like Google Drive, with documents organized in folders or as an internal website. I recommend investing some effort in creating better infrastructure and user experience, as it can enable more people to access and benefit from data. A solid setup will make it easier for more people to access and benefit from the data, turning it into a real asset rather than a digital junk drawer.
Simply collecting and putting data in one place will not create any value. Regardless of how you implement your Data Foundation, with papers on the wall, in Google Drive, in Confluence, or with a nicely designed internal website, I have identified the following requirements that a Data Foundation needs to have:
- It is the single point of truth for all relevant architectural data. People should be able to go to one place and get the most relevant data.
- It is curated for quality so people can trust the data. Simply dumping data into one place will not help. You need to own curation to ensure that data are correct. You also should provide links to data sources so people can verify the facts.
- It is curated for usability so people stay focused on valuable details. You must filter out useless or less relevant details, focusing on the essence. Investing in the UX design of documents or tools you create helps.
- It is kept up to date, ideally in an automated fashion (or in a semi-automated repeatable way).
- It is accessible to the whole organization. I genuinely believe that when you give employees access to information generally reserved for specialists, architects, or “higher levels,” they get more done independently. They can work faster without stopping to ask for information and approval. And they make better decisions without needing input from architects or the top.
- It is used in decision-making. Having nicely curated and valuable data has zero value if you cannot ensure that such data inform vital decisions.
My approach to building the Data Foundation is like creating a map. Maps are some of the most crucial documents in human history—they help us store and exchange knowledge about space and place. One thing all maps do is provide readers with a sense of orientation. And that, in a nutshell, is what Data Foundation should offer people in your organization: a sense of orientation in a waste space of technology, organizational and business topics. The map metaphor is also helpful as maps come with multiple layers. Similarly, the architecture of Data Foundation should give readers data layers about systems that describe their sizes, connections, quality, security, or human activity. It’s like having a trusty map that shows you where the treasure is and warns you about the dragons.
Building Data Foundation
While each organization has its own quirky set of data, here are some tips I’ve found helpful in forming the architecture Data Foundation:
-
Start with the source code. My motto is “Talk is expensive. Show me the code.” Because let’s face it, code never lies—people, on the other hand, might forget a detail or two. I scan source code as soon as possible using tools like Sokrates. Modern IT enterprises store almost everything as code. It’s the richest and most up-to-date documentation on what’s happening. Quick source code scans can reveal that your “simple” system is actually a digital spaghetti monster.
-
Connect with finance and governance teams. My second motto is “Follow the money!” You’d be amazed what you can learn from finance data (minus the sensitive parts, like revenue projections—let’s keep those secrets safe). Cloud billing reports and tech usage trends are collected anyway. Extract and connect these to get new insights without pestering people for more details.
-
Maintain a culture of transparency. Sharing fewer data with everyone is like handing out fewer candies at Halloween—easier and less chaotic. Keep it simple, avoid complex authorization mechanisms, and you’ll have fewer data goblins to manage.
-
Own the curation. People need to trust your data like they trust their morning coffee to wake them up. Spend time understanding data sets, curate them, and ensure they’re consistently presented. Think of yourself as the master curator and chief UX designer of the Data Foundation.
-
Use simple and easy-to-maintain infrastructures. For example, I publish the results of Sokrates analyses and other data tools as static resources on our enterprise GitHub pages. Avoid the headache of complex databases and backend software. In the Architecture Dashboard Examples repository, you’ll find the source code for building the Architecture Data Dashboard. The dashboard is a simple static website generated from JSON files and published via GitHub pages.
These tips might just save you from drowning in the sea of data chaos and make your architectural life a bit smoother—or at least give you a few laughs along the way.
Using Architecture Data Foundation
The Data Foundation can churn out data by the bucketful. Think of it like an atlas or a map—it’s great for finding your bearings and understanding the lay of the land. But, with the right mindset, you can turn that data into a treasure trove of insights.
Interpreting and using data requires a bit of effort—think of it as a detective game where the data holds the answers, but you need to come armed with the right questions. Here are some of the questions you should ask when you’ve got a pile of data at your fingertips:
-
Are we all rowing in the same direction? Source code overviews, public cloud usage explorers, or tech radars can highlight when systems and teams are out of sync, sparking heated debates that lead to real action.
-
Are we making the most of our technology? Comparing usage trends between teams can reveal fascinating outliers—both the virtuosos and those who are… let’s say, still tuning their guitars.
-
Are there signs our code might need a little TLC (tender, loving care)? Look out for oversized systems, rampant duplication, and files that go on longer than your Aunt Marge’s vacation slideshows.
-
Productivity trends: is more really more, or is more actually less? For instance, comparing the number of git merges to the number of developers can reveal if our dev processes are scalable. When scaling up teams, we aim to speed up delivery, but without proper structure, we might end up with a digital mosh pit.
-
Are we collaborating the way we want to? Repository analysis can reveal team topologies and unwanted dependencies. Sometimes, teams collaborate like a well-oiled machine; other times, it’s more like a group project in high school.
-
Are we working on what we really want to? We may aspire to innovate, but if we’re spending most of our time wrestling with legacy maintenance, we might need to rethink our priorities.
So there you have it. The data’s ready to spill its secrets—you need to know the right questions to ask. So, what is your question?
To Probe Further
- Open-source architecture dashboard examples
- Sokrates, an open-source polyglot source code examination tool
Appendix: Examples of Insights From Source Code Analyses
Figures 6 to 10 show some insights from source code analyses with Sokrates.
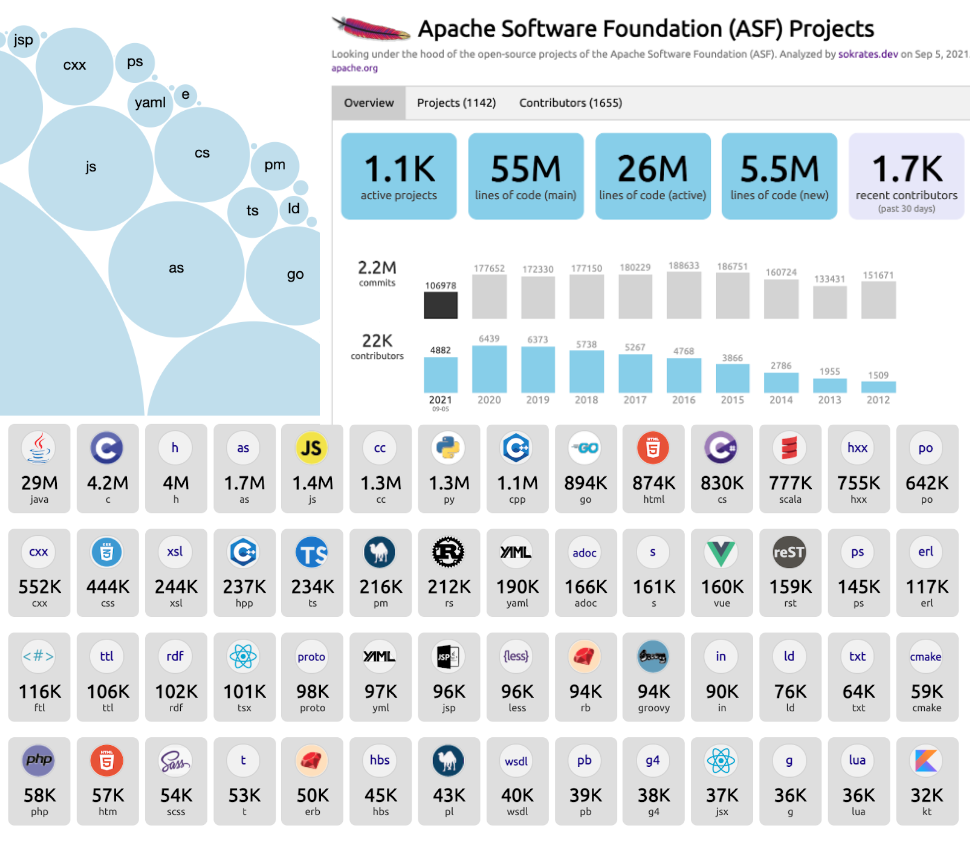
Figure 6: Sokrates can instantly create a helicopter view of the technology landscape, programming languages, active contributors, and commit trends.
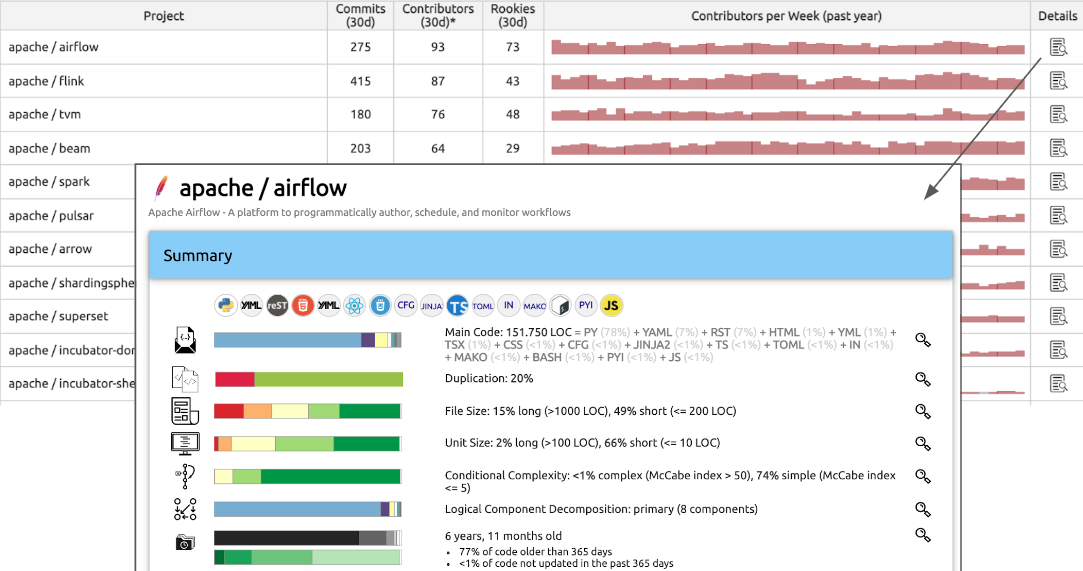
Figure 7: Sokrates can show detailed code and contributors’ trends per repository, enabling zooming in each repository up to the code level.
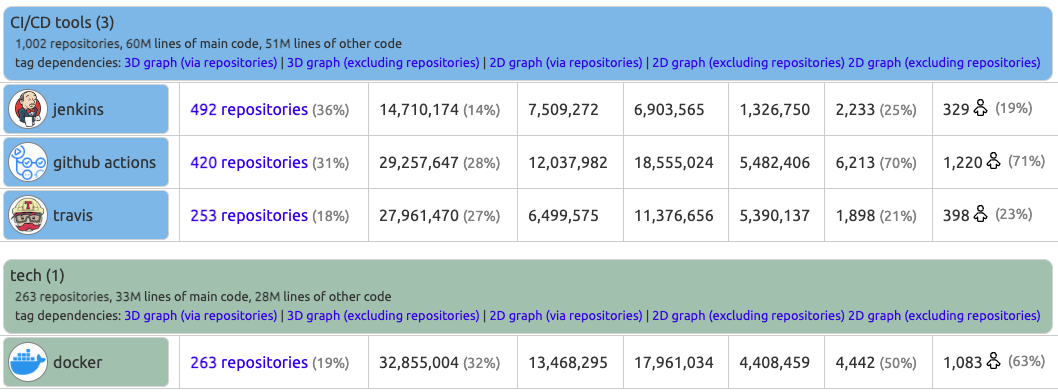
Figure 8: Sokrates can create a tech radar by tagging projects with identified technologies.
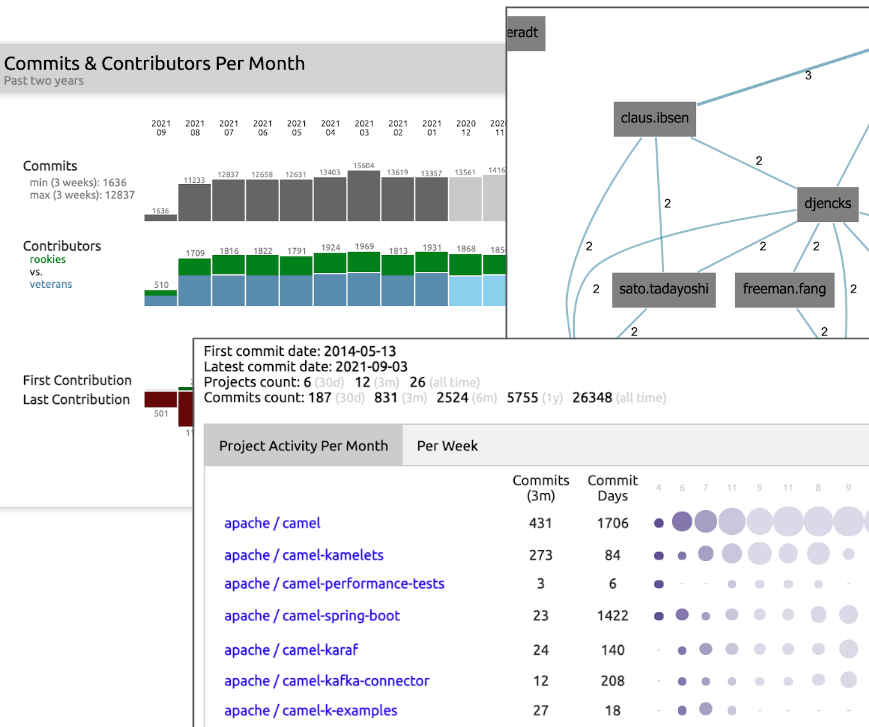
Figure 9: Sokrates can show contributor trends, distribution of “veterans” and “rookies,” and dependencies between people and repositories, enabling zooming in into patterns of the contribution of individual contributors.

Figure 10: Sokrates can reveal the team topologies by plotting 2D and 3D graphs of dependencies that people create through working on the same repositories in the same period.
Questions to Consider
Using data can significantly improve the efficiency and impact of architectural practice. But there are no simple tools that can instantly provide you insights. Ask yourself the following questions:
- Have you considered using open-source tools like Sokrates to gain architectural insights from data sources? Why or why not?
- What are your views on the reliability and scalability of manual documentation?
- What steps would you take to create an architecture Data Foundation in your organization?
- Are there untapped data sources within your organization that could inform your architectural decisions?
- How could you automate gathering data for architectural insights in your organization?
- What examples can you provide of the data you’ve used to gain reliable information about technology in your organization?
- How would you examine public cloud billing reports, incident reports, or key business metrics for architectural insights?
- How can you ensure your data is reliable and up-to-date?
- Do you collaborate with finance and governance teams to incorporate financial and vibrancy data into your data analysis?
- Is there a culture of transparency in your organization?
Structure ← Grounded Architecture: Introduction |
Structure People Foundation → |